可提供

如果你有志或已经考取为计算机相关专业的研究生,本毕业设计将为你提供:
- 完成本次毕业设计,可用于一次 软件著作权 的申请。
- 在完成本次毕业设计的过程中,如能有创新性想法,可用于申请 专利;
- 如能实现创新想法并实现,如能达到预期效果,可用于撰写 科研论文;
所有上述成果可用于 奖学金申请。
基本内容
- 涉及算法的设计及实现,主要涉及: 进化优化算法 及 深度学习
- 应用问题的建模及求解,主要涉及:锂离子电池寿命估计、网络流量预测、网络流量异常检测、计算视觉等。
基本要求
- 熟练掌握至少一门编程语言:Python、Java等
- 有良好的英语基础,能阅读相关英语文献(论文,源代码说明等)
- 了解机器学习的基本概念及常用算法库
其他要求:需要至少 每周参与一次线下交流 ,并能使用 版本控制工具git ,采用 Pull request方式 提交当周任务。可使用 Markdown 语法完成笔记和每周日志。如果你选修过我的 软件工具与环境(高级)课程,这些工具和流程应该会熟悉。
注意:毕业设计题目可尽量靠近未来导师研究方向,具体题目可商议!如果你报考本校,并希望加入 IVCG Group,本毕业设计可作为研究生研究方向的预研。
2021年春季毕业设计举例
郝晓斌:进化注意力机制LSTM算法的研究及其对时间序列预测问题的应用
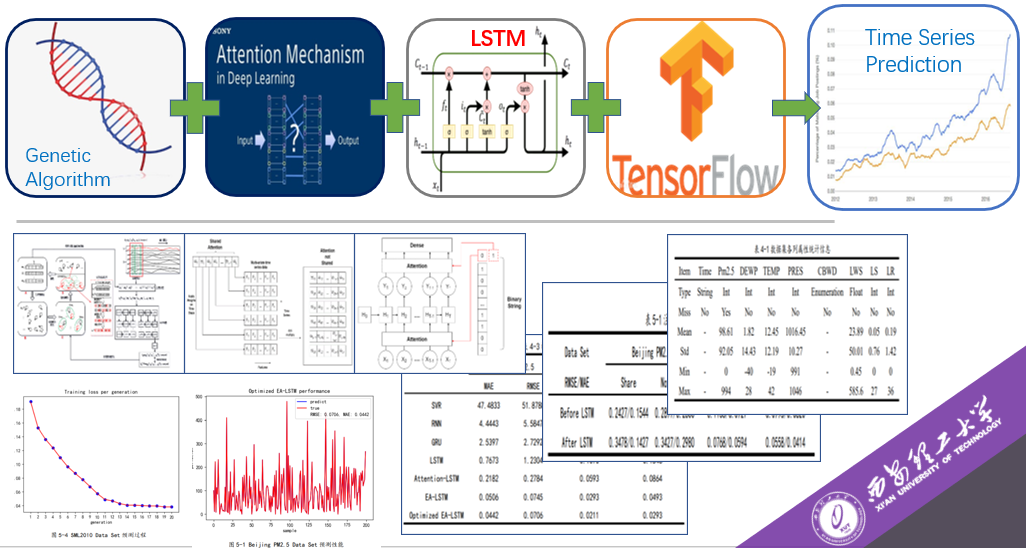
时间序列预测问题是一个备受关注的热点问题。近年来,随着深度学习的发展,应用深度学习对时间序列进行预测,特别是使用长短期记忆神经网络(Long Short Term Memory network, LSTM)进行预测方面,取得的效果斐然。然而,虽然LSTM可捕获时间序列中的长期依赖关系,但它在多个时间步长内对子窗口特征给予不同程度的关注能力较弱。此外,神经网络配置过程较为繁琐,网络配置过程耗费时间长。
为有效处理上述问题,受认知神经科学思想的指引,本论文以长短期记忆神经网络中引入注意力机制的算法为研究对象,用于改善传统LSTM的注意力分散缺陷。并实现一种基于进化算法优化注意力层的优化框架,通过与传统LSTM进行合作学习的方式,完成注意力层中相应权值的优化。此外,为更好的配置注意力层参数权重和注意力层位置跳转,本论文在基于进化计算的思想上,设计了一种随机机制多注意力层参数学习方法。该方法尝试将注意力层的跳转与时序变换,编入进化模型的决策空间中。旨在更好完成注意力LSTM网络的自动配置、有效避免传统基于梯度的参数学习方法过早收敛或陷入局部最优的问题,从而提高该模型的整体性能。
本论文使用Tensorflow2.0深度学习框架实现了基于进化注意力机制的LSTM算法,并在此基础上实现了所提出的改进算法。并通过与传统的机器学习模型SVR、循环神经网络(Recurrent Neural Network, RNN)、LSTM、Attention-LSTM、门控循环单元神经网络(Gated Recurrent Neural network, GRU)等基本的神经网络模型,对不同时间序列预测问题进行实验对比。实验结果表明,所提出的算法可自动配置出注意力层的位置跳转与相应权值。且该模型无论是预测性能,还是预测准确性方面都取得了良好的结果。
刘震:基于GRU的网络流量预测方法的研究实现与改进
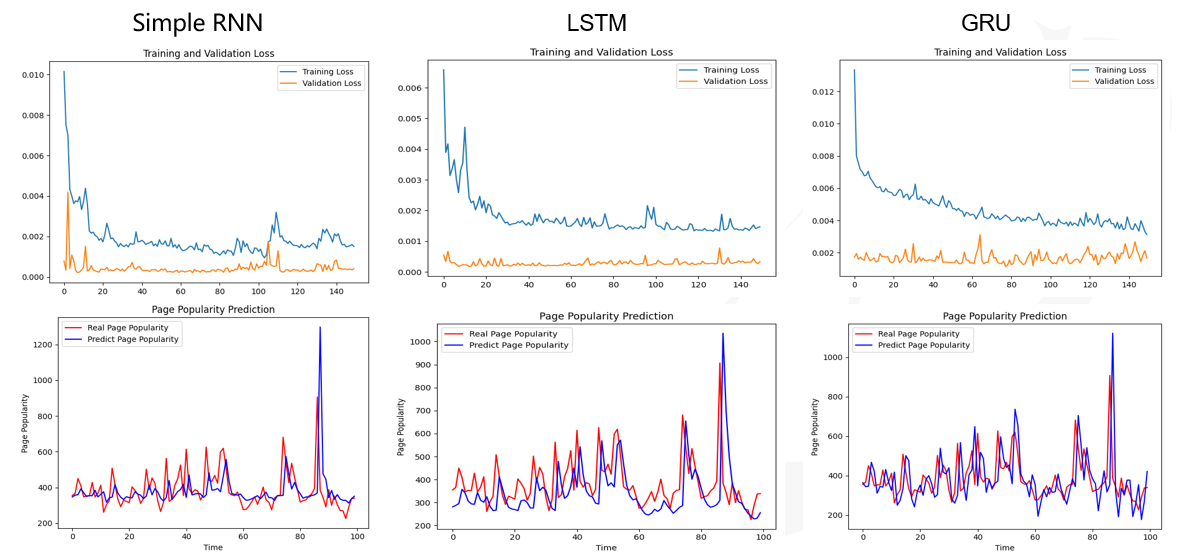
移动互联网在为人类社会提供巨大便利的同时,其本身的流量数据也正爆炸性地增长。为了缓解这一问题,本文提出了一种网络流量预测模型,该模型的预测结果可作为网络提供商合理控制网络流量、分配网络资源的有效依据。
本文以门限循环单元(GRU)为核心,建立网络流量数据的预测模型,并在此预测模型的基础上进行了改进以提高预测准确度。
最初,通过对比简单循环神经网络(SimpleRNN)、长短期记忆网络(LSTM)和GRU对原始数据的学习能力,决定选用学习效果最佳的GRU作为实验的核心模型。接着,为了缓解因时间序列过长而导致的特征遗忘,采用序列到序列(Seq2Seq)模型提高预测准确度。
由于对改进后模型的预测效果不满意,又利用统计学方法,提取网络流量数据的特征。同时,在基于GRU的Seq2Seq模型中引入注意力机制,在训练过程中添加损失函数正则化和梯度裁剪,进一步减小了预测误差。最终,得到了有借鉴价值的未来两个月的网络流量预测数据。
结果表明,在网络流量数据预测问题中,使用GRU、Seq2Seq和注意力机制的组合模型,能够获得有参照价值的预测数据,这对进行网络空间的管理和维护具有重要意义。
桂鹏飞: 基于LSTM-Autoencoder的网络流量异常检测问题的研究与实现
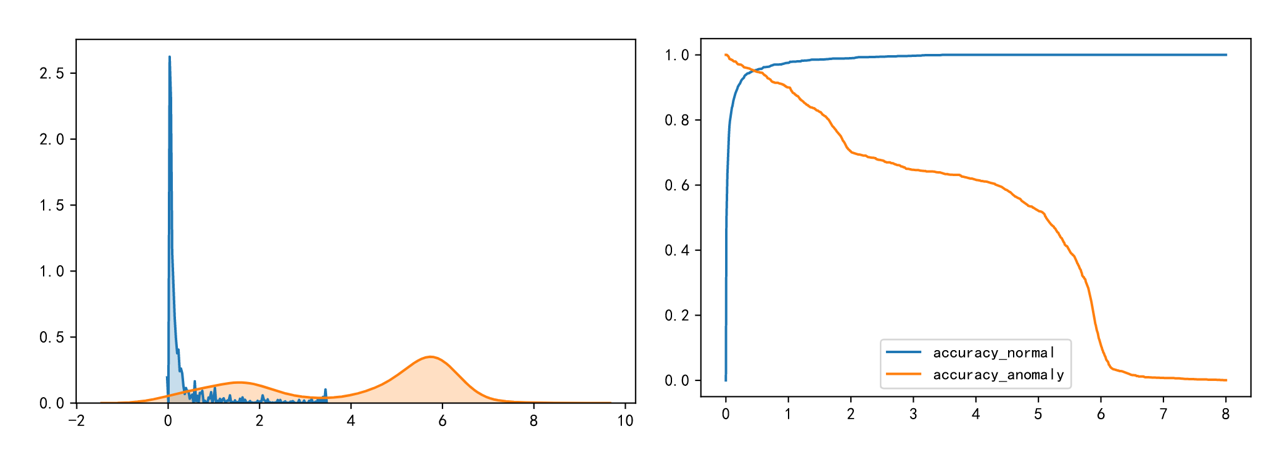
网络流量中常有恶意攻击的流量数据,这些数据往往与正常的网络流量数据不一致,如何能区别开正常网络流量数据和异常网络流量数据是网络安全中的一个重要问题。
本文采用LSTM自编码器来实现对网络正常流量数据和异常流量数据的区分,自编码器模型可以将网络流量数据先编码再解码得到一个编码前的数据和编码后的数据重构误差,而正常网络流量数据的重构误差和异常网络流量数据的重构误差差距是较大,可从这个角度采用无监督学习来实现网络流量异常数据的检测。通过训练模型得到重构误差的一个阈值来区别网络中的正常和异常流量数据。
由于网络流量数据集(比如NSL-KDD数据集)一般具有较高的特征维度,会降低机器学习的效率,因此提取有效的特征较为关键,可降低冗余数据对实验结果的影响,以及对于提高机器学习的速率和准确率。本文所采用的自编码器模型训练多次达到稳定的一个结构时,自编码器模型的编码数据往往是编码前数据具有代表性的一部分,从这个角度说,编码的数据相当于进行了一个降维操作。本文将编码降维的方式与传统的PCA降维方式进行了一个比较,采用SVM对压缩后的网络流量特征进行二元分类,实验结果表明编码降维的数据特征具有较好的实现效果。