概述
在平时实验的过程中,花费一些时间和经历对当前的实验进行追踪和管理其实非常必要。一个好的科研实验追踪与管理,可更好的组织实验、追踪数据并可重复实验。 此外,这种科研实验的追踪和管理体系,也是你和导师进行实验交流的必要手段之一。 因此,这里描述一下实验室内的所使用的简单的实验追踪与管理系统。
![]()
实验的追踪和管理的一般流程,源自: comet.com
工程目录
当开始一个实验的时候,第一步就是需要建立一个工程目录。一个典型的工程目录应当包括源代码、配置文件、日志文件和实验的结果文件等。目前,所使用的一个工程目录树和相应文件和目录的作用,可简单描述如下:
Your experimental path/
├── .gitignore # 用于定义git版本库中需要忽略的文件
├── cfgs # 配置文件目录,存放实验所使用的 .yaml 文件
├── paper # 论文目录,存放论文文件
│ └── manuscript
│ ├── main.tex
│ └── fig
├── results # 最终实验结果存放目录
│ └── MIT
│ ├── capacity
│ └── ...
├── results_ # 临时实验结果存放目录,最后有一个下划线
│ └── MIT
│ ├── capacity
│ └── ...
└── src # 实验所使用源代码的根目录
├── experiment
│ └── ...
...
└── utils
以下,结合工作目录树,简要介绍一下安排实验的各个文件和目录的意义。
- .gitignore 文件:git版本控制中所需要忽略的文件。以目前实验室常见的实验为例,需要添加Python项目中的临时文件和Latex中的临时文件。换句话说,这些文件都不要进入到版本库当中。此外,.gitignore 当中所需要增加目录下的临时实验结果存放文件 ./result,因为用于存放临时实验文件,也不必添加到版本库当中。对于不同语言以及Latex所使用的.gitignore如何定义,或者其他类型源代码的定义,可参考: A collection of .gitignore templates 项目。
- cfgs目录:用于存放实验相关的配置文件,实验的环境和超参数配置等,会在后面详述。
- paper目录:存放与当前实验相关的论文,前期实验的时候,也可放一些有关的笔记等。
- results_目录:实验的临时目录 这部分不放入版本库中。
- results目录:最终的实验,也就是在论文当中用于展示的实验,这部分需要放入到版本库中。此外,paper目录中的论文也可直接调用这里的内容。
- src目录:源代码的根目录,例如使用Pycharm的化,需将源代码根目录设置在此目录下。
版本控制
在工程目录建立后并添加了基本的实验与文档内容后,这时就可以将整个工程放到版本控制中进行管理。首先需要注意,使用版本控制需要 注意一些问题,例如不要把版本控制工具当成是备份工具;此外,不要commit不能运行的代码等等。使用版本控制工具,实际上有两方面的作用。一方面作用于个人,帮助你管理实验过程中的各个版本。另一方面,在于方便与同学或导师进行合作。例如:导师可使用 pull request 方式,管理给你的阶段性任务。所以,无论是站在使用目的还是功能目的的角度上,切记 使用分支功能来隔离不同目的的项目。 并且,做好分支的记录和管理工作,以面最后出现太多分支,造成合并困难。
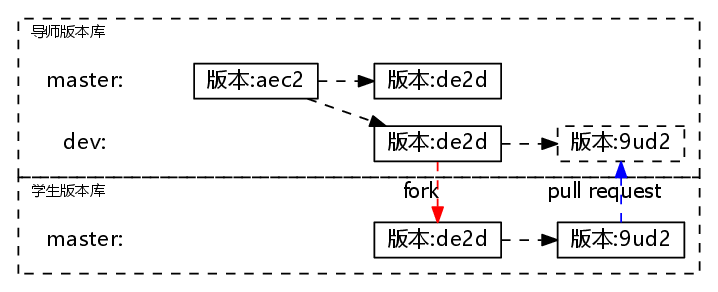
使用版本控制的工作流
一个简单的科研工作流如上图所示。首先,由导师在自己的版本库当中建立master和dev分支,然后学生可将指定版本fork到自己的版本库中进行开发。开发完毕,形成一个新的版本后,再向导师版本库的dev分支发送pull request请求。
配置管理
如果使用Python,实际上有一个 input argparse 可获取命令行的各项参数,从一些开源项目当中其实也能看到确实使用 argparse 将所需参数传递。但是在实际使用过程中,如果实验的参数包括配置参数、模型参数等等数量过多的情况下,采用这种方式不易管理参数。所以,最好有一个文本文件能将实验所有的参数进行存储,在实验的时候读入程序。这里参考 知乎的一个帖子,推荐了一个 OpenPCDDet中对配置进行管理的方法。将所有的配置文件写到 YAML 文件当中,然后读入程序。目前,对于较为简单场景下的参数管理,这种方式最为适合。
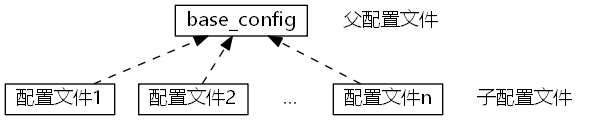
配置文件的继承关系
使用该配置文件方式有一个类似于类的集成关系,下层配置文件中指派了父配置文件,即 _BASE_CONFIG_: 父配置文件地址。则读取子配置文件,会自动将父配置文件里的内容一并读入进来。所以,base_config文件当中一般配置一些每个实验都会用到的公共信息。
实验流程
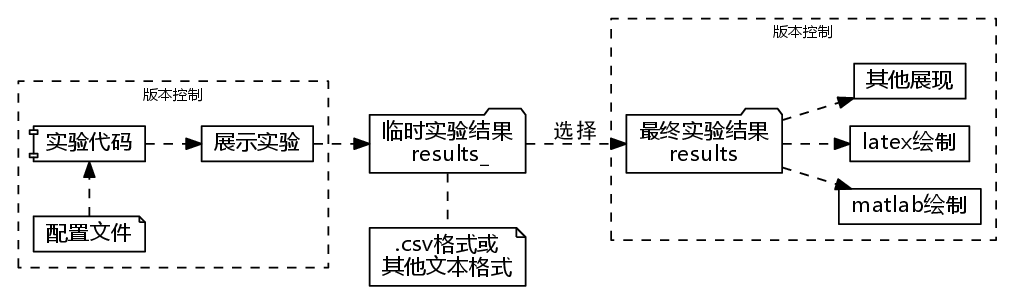
整体实验流程概览
实验流程按照产出的结果走向如上图所示,首先实验的程序代码,读取相关配置,展示实验结果。每次的实验结果最终会存储在临时的实验结果文件目录result_中,待实验结果满意后,将相关的结果移至最终实验结果中。 注意:results存储的仅是实验的数据文件,而不是绘制的实验结果图。这样方便后期撰写论文的时候,使用其他手段对图或表进行绘制。在读取实验结果的时候,可使用一个简单的函数,获取临时实验或者最终实验结果,举例如下:
def get_result_path(results_type, results_name, file_extension, cfg, is_temp=True):
base_file_name = results_type + '/' + results_name + '.' + file_extension
path = cfg.root_path_str + '/' + cfg.result_path
if is_temp:
path = path + '_/' + cfg.data_name + '/' + base_file_name
else:
path = path + '/' + cfg .data_name + '/' + base_file_name
return path
注意,在实验过程中,请务必将 实验逻辑 和 实验展示 进行解耦。实验代码部分,负责读入配置,产生实验结果,然后存入 results_目录。而展示实验部分的代码,则负责从 results_ 或者 results 目录中读取实验结果,并进行绘制。具体流程如下图:
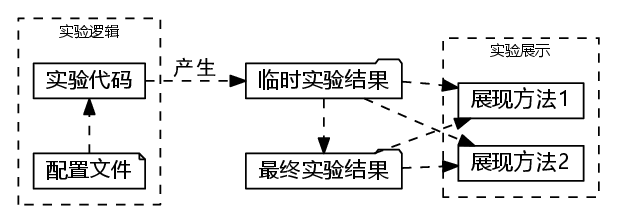
实验逻辑与实验展示进行解耦
实验逻辑完成后,按照实验类型+实验名称的形式,存入到结果文件当中,基本的代码逻辑如下:
experiment_type="generation"
experiment_name="GAN_experiment"
path = get_result_path(experiment_type, experiment_name, 'csv', cfg)
write_matrix_to_file(path, feature)
采用这样的方式,可避免后期为了看某个实验结果,再重新将实验跑一边的情况。